Distributed Computing: Message Passing Interface (MPI)
Contents
Distributed Computing: Message Passing Interface (MPI)#
Distributed vs MPI#
Distributed
can be convenient, in particular for “ad-hoc” distributed computing (e.g. data processing)
master-worker model often naturally aligns with the structure of scientific computations
can be used interactively in a REPL / in Jupyter etc.
no external dependencies, built-in library
higher overhead than MPI and doesn’t scale as well (doesn’t utilizie Infiniband -> slower communication)
MPI
de-facto industry standard for massively parallel computing, e.g. large scale distributed computing
known to scale well up to thousands of compute nodes
does utilize Infiniband
Programming model can be more challenging
No (or poor) interactivity (see MPIClusterManager.jl)
MPI and MPI.jl#
MPI: A standard with several specific implementations (e.g. OpenMPI, IntelMPI, MPICH)
MPI.jl: Julia package and interface to MPI implementations
How to get an MPI implementation?#
Will be automatically downloaded when installing MPI.jl (
] add MPI).Alternative: Install manually (e.g. from https://www.open-mpi.org/) and point MPI.jl to the manual installation via
ENV["JULIA_MPI_BINARY"]="system".On clusters (e.g. Hawk): Often provided as a module. If it doesn’t work out of the box then use
ENV["JULIA_MPI_BINARY"]="system"and partners.
Programming model and execution#
MPI programming model:
conceptually, all processes execute the same program.
different behavior for processes must be implementend with conditionals (e.g. using rank information)
individual processes flow at there own pace (they can get out of sync).
selecting the concrete number of processes is deferred to “runtime”.
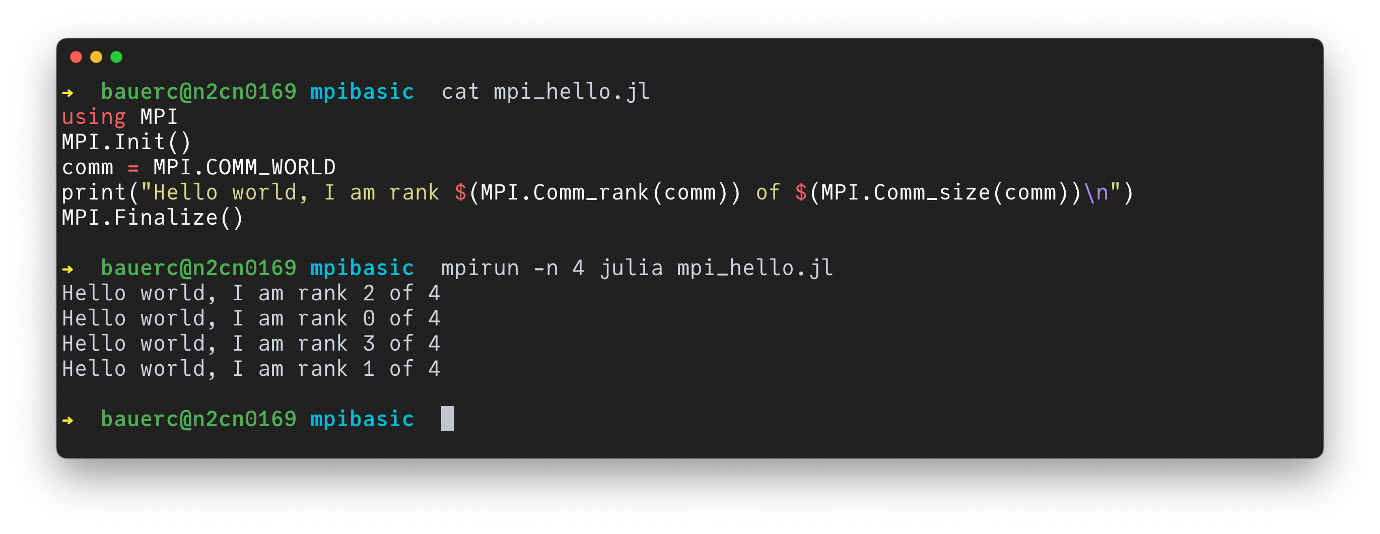
Example: Hello World#
# file: mpi_hello.jl
using MPI
MPI.Init()
comm = MPI.COMM_WORLD
print("Hello world, I am rank $(MPI.Comm_rank(comm)) of $(MPI.Comm_size(comm))\n")
MPI.Finalize()
Fundamental MPI functions#
MPI.Init() and MPI.Finalize(): Always at the top or bottom of your code, respectively.
MPI.COMM_WORLD: default communicator (group of MPI processes) which includes all processes created when launching the program
MPI.Comm_rank(comm): rank of the process calling this function
MPI.Comm_size(comm): total number of processes in the given communicator
Naming convention in MPI.jl
If possible,
MPI_*in C ->MPI.*in JuliaExamples:
MPI_COMM_WORLD->MPI.COMM_WORLDMPI_Comm_size->MPI.Comm_size
Running an MPI code#
MPI implementations provide mpirun and/or mpiexec to run MPI applications.
mpirun -n <number_of_processes) julia --project mycode.jl
(If you want to use the MPI that automatically ships with MPI.jl you should use the mpiexecjl wrapper.)
Basic communication#
Two-sided, blocking#
MPI.Send(data, destination, tag, communicator)andMPI.Recv(data, origin, tag, communicator)data: For example an array (buffer)destination/origin: Rank of the target processtag: “optional” integer (just set it to zero)communicator
MPI.Recv(data, origin, tag, communicator)data: For example an array (buffer)destination/origin: Rank of source processtag: “optional” integer (just set it to zero)communicator
Blocking, so be aware of deadlocks! (There are MPI.Sendrecv! and the non-blocking variants MPI.Isend and MPI.Irecv!.)
Collectives#
Synchronization:
MPI.Barrier(comm)
Data movement:
one-to-many and many-to-many (e.g. broadcast, scatter, gather, all to all)
result = MPI.Bcast!(data, root, communicator)data: For example an array (buffer)root: root rank (should hold the data)communicator
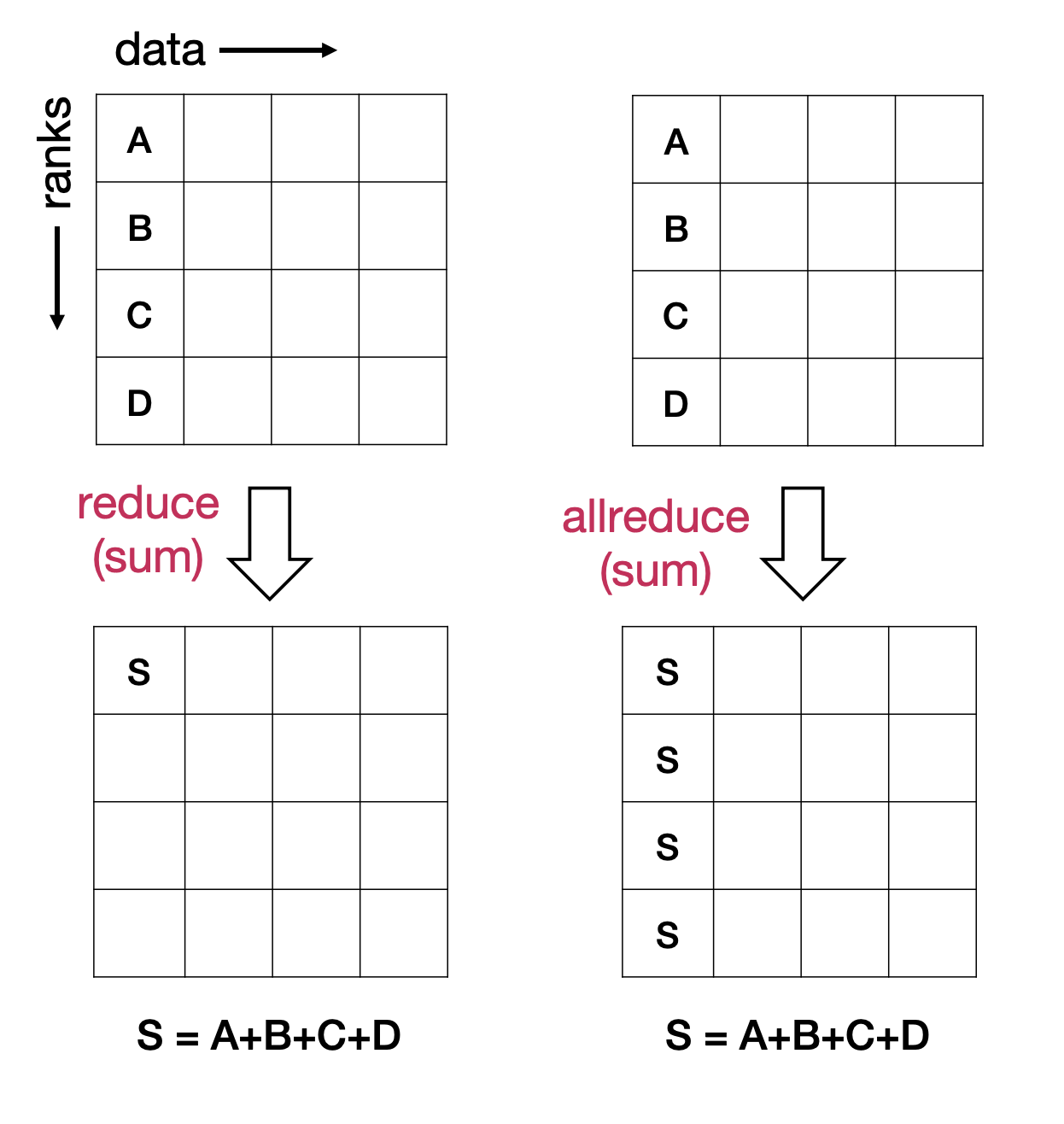
Reduction:
result = MPI.Reduce(local_data, op, root, communicator)local_data: For example an array (buffer)op: reducer function, e.g.+root: root rank (will eventually hold the reduction result)communicator
Conveniences of MPI.jl#
Julia MPI functions can have less function arguments than C counterparts if some of them are deducible
MPI functions can often handle data of built-in and custom Julia types (i.e. custom
structs)MPI.Types.create_*constructor functions (create_vector,create_subarray,create_struct, etc.) get automatically called under the hood.
MPI Functions can often handle built-in and custom Julia functions, e.g. as a reducer function in
MPI.Reduce.
High-level tools#
PartitionedArrays.jl: Data-oriented parallel implementation of partitioned vectors and sparse matrices needed in FD, FV, and FE simulations.
Elemental.jl: A package for dense and sparse distributed linear algebra and optimization.
PETSc.jl: Suite of data structures and routines for the scalable (parallel) solution of scientific applications modeled by partial differential equations. (original website)